对YOLOv2理解和复现(backbone并没用darknet19)的一点记录。
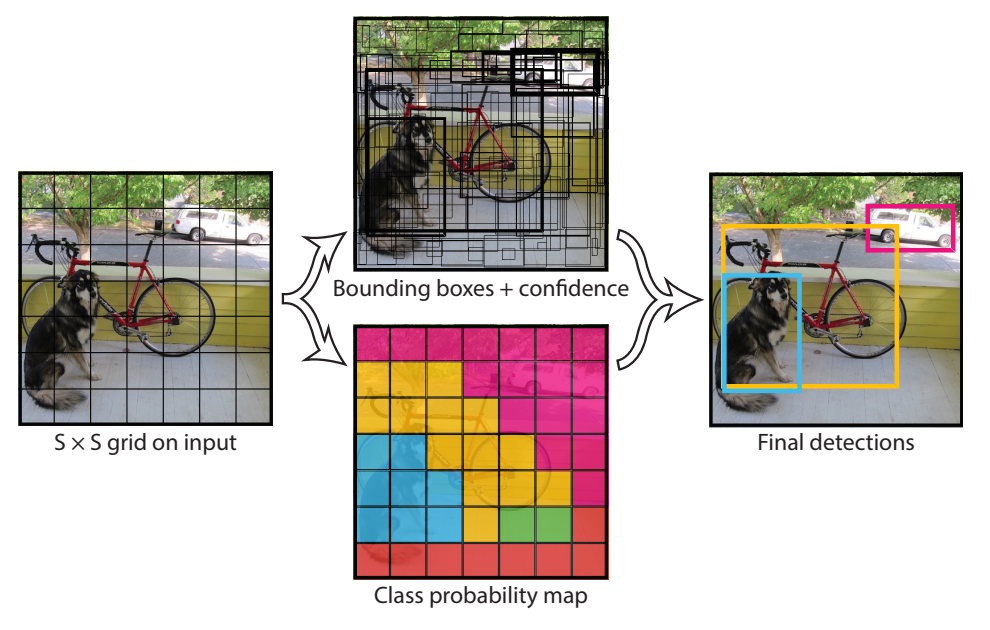
YOLOv2将检测作为一个分类+回归问题:将图片分割为个grid,每一个grid单元预测个bounding box、置信度、个类别概率,这些会被编码为一个的矩阵。
YOLOv2整体网络
主要可分为以下三个方面:
backbone为全卷积网络FCN,整体网络降采样32倍,有利于多尺度训练(Multi-Scale Training);使用
leaky ReLU作为激活函数:输出解码:
backbone输出为的三维矩阵。其中:- 超参数:每个
grid的bounding boxes的数量; - 类别数(不包含背景,所有单类的话这个分支可以去掉,损失函数部分也对应去掉),每位数对应相应类别的概率预测(之所以要定义为
Object的条件概率,是因为总损失函数里,只有当Object中心落到对应的grid中时,该grid才计算分类损失),故该类别预测向量可以通过softmax函数转化为之间类别概率:实现上,为了防止数值溢出,一般会减去最大值的操作。 - 4个
bounding box对应的坐标信息:中心点及宽高,考虑到模型训练过程的稳定性,不能像region proposal算法那样,不约束预测中心的位置:并且YOLO把物体的检测任务根据物品中心分配到对应的grid去,所以理应把预测中心的位置限制在当前grid中,故提出了中心坐标根据grid的左上角坐标的偏移进行预测,宽高的预测则是基于anchors进行比例伸缩: - 1个IOU预测值:,这里指:只有当
Object中心落到对应的grid中时,该grid才计算该预测值与实际IOU的损失,否则计算该预测值与0的损失。此时,预测值也约束为之间:
- 超参数:每个
损失函数
YOLO系列的精髓在于他的思想简单直接,使用的技巧也很纯粹。其中的损失函数部分,更是YOLO系列理解和实现中最重要的部分:
上面的公式,只是Darknet损失函数的想法,实际代码和上面公式有出入(公式9,10,11计算IOU和类别概率损失是一致的)。在Darknet的源码中,(x, y, w, h)损失的计算为:
1 | float tx = (truth.x*lw - i); |
其中,scale = 2 - truth.w * truth.h,truth.w/h是归一化后的宽/高,中心坐标(x, y)损失项的计算和上面公式7一致(除了scale),但(w, h)损失项的计算则有出入:
其实还有一个scale,提升对小目标的误差的敏感程度。
response box的界定
比较难理解的地方在于:和的规定、这些系数的选取。 我们以输出矩阵为的情况进行举例讲解:
- 的解释:如下图所示,原图的输入,经过倍的下采样,得到的输出。YOLO系列算法中,将目标物体的检测任务,分配到输出层的对应
grid中:原图目标检测框的中心点位置,落在的输出特征图中的第个grid中,而这个grid的第个anchor预测框(Darknet源码实现是预定义anchor box)与真实框的IOU最大,故第个grid的第个anchor预测框负责该物体的检测。也就是,目标物体中心点所在的grid中,个候选框中与目标框IOU最大的预测框/预定义anchor box,才用来预测该目标候选框:此grid、此anchor对应公式中的情况,其他情况。

这个图来自目标检测网络之 YOLOv3,
的解释:上面解释了的情况,并不是就是,只有预测框与所有的真实目标框的IOU都小于一定阈值(darknet YOLO9000 thresh是0.6,darknet YOLOv3 ignore thresh 是0.7),才是的情况,此时我们才认为该grid、该anchor的预测框没有任何目标存在,为background区域,需要计算背景IOU损失!而大于这个阈值而又不是的anchor,是不用计算损失的。
没有目标存在的grid、anchor,需要使其预测IOU趋于0,也就是损失部分,而有目标的grid、anchor,则需要其预测的IOU趋于1、预测的物品类别概率正确、预测框位置准确,也就是对应的、、损失部分。作者认为,背景区域比较多,所以背景区域带来的IOU损失权重应该比较小:;而目标区域的位置误差只有4维,而物品类别误差有20/80维,那么设置大一些。(这是可以调参的部分;同时,复现的人会将focal loss用在IOU的损失函数这块上,因为只有这块有背景和前景的失衡情况)
损失函数里对宽高进行了开方,是为了缓和大小不同的box预测时的偏移差异:相比于大bbox预测偏一点,小box预测偏一点更不能忍受(这里用相对尺度会不会更好一些?)。
重要的额外说明:
实际实现中,为了使前期训练(前12800张训练图片)时,位置的回归具有一定的稳定性,加入了额外的损失项,可参考下文。

这个图来自图解YOLO,虽然针对YOLO,但是可以参考一下。
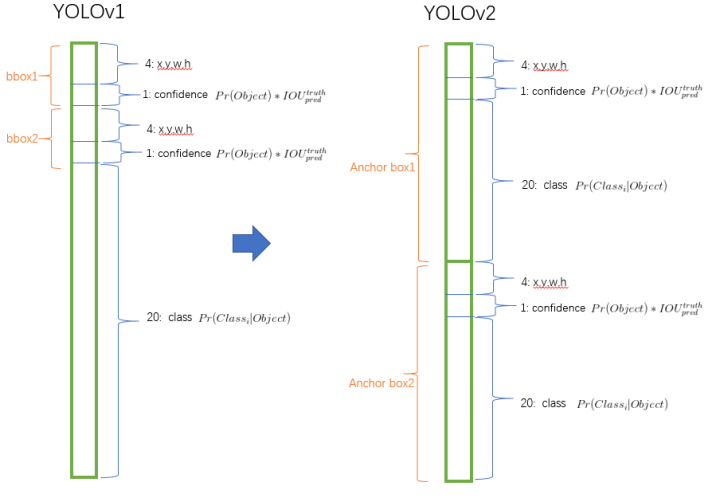
这个图来自YOLO2,实际YOLOv2的论文中,先验box为5个。
YOLOv2的训练与测试
训练:
- 先用ImageNet 224*224进行分类预训练backbone;
- 再用ImageNet 448*448进行fine-tuning训练backbone;
- 最后切换为检测任务,fine-tuning整体模型;
- 前期12800张图片的损失函数,增加损失项:
其中,是预测框的先验框,是中心点;以此来使得前期所有的预测框往先验框大小靠近,往grid中心点移动。稳定前期训练,且有利于后期预测框的学习(预测位置在0.5左右,刚好是sigmoid梯度最大的地方)。
测试:
- 测试时,计算指定类别的置信度:
大于一定阈值的话,则认为检测到目标。
- 对所有grid进行如上计算及阈值过滤,然后进行NMS,得到最终检测结果。
YOLOv2周边
包含聚类anchors、YOLOv2的局限、单类检测的讨论。
聚类anchors
用k-means(每张图片的所有目标的(W, H)作为输入特征,
目标框与聚类中心的作为距离评价指标)进行聚类,
以k个聚类中心的尺寸(W, H)作为网络预定义的k个anchors的尺寸。
YOLOv2的局限
最终检测的特征图相对原图的缩放倍数为32倍,不利于小物体检测, 在YOLOv3用 FPN + 基于resize的上采样信息融合 + 3种下采样率的分支 改进。
单类检测
如果是单类检测器,也就是说其实这时只是为了定位,以提供后续处理, 那么可以删除网络中的分类预测channel(单类也就是1个channel),然后损失函数里也不需要分支。
实现代码
基于tensorflow keras实现,包含中文注释讲解。

